
Z wielką mocą (AI) sztucznej inteligencji generatywnej wiąże się wielka odpowiedzialność. Oto jak badacze zajmują się etycznymi kwestiami i wyzwaniami – największymi pytaniami naszych czasów.
Wraz z ogłaszaniem codziennie nowych odkryć dotyczących możliwości sztucznej inteligencji generatywnej, ludzie w różnych branżach starają się zbadać, w jakim stopniu AI może napędzać nie tylko nasze codzienne zadania, ale także większe, bardziej złożone projekty. Jednakże, wraz z tymi odkryciami pojawiają się obawy i pytania dotyczące sposobu regulowania wykorzystania sztucznej inteligencji generatywnej. Jednocześnie pojawiają się pozwy przeciwko OpenAI, a etyczne wykorzystanie sztucznej inteligencji generatywnej stanowi palący problem. W miarę ewolucji aktualizowanych modeli AI, regulacje prawne wciąż pozostają w obszarze szarej strefy. To, co możemy zrobić teraz, to uczyć się o wyzwaniach związanych z wykorzystaniem potężnej technologii i dowiedzieć się, jakie zabezpieczenia są wprowadzane przeciwko nadużyciom technologii, która ma ogromny potencjał.
Wykorzystajmy sztuczną inteligencję do zwalczania manipulacji za pomocą AI.
Od sytuacji, takich jak prawnicy powołujący się na fałszywe przypadki stworzone przez ChatGPT, po studentów używających AI chatbotów do pisania swoich prac, a nawet generowane przez AI obrazy z aresztowania Donalda Trumpa, staje się coraz trudniejsze odróżnienie, co stanowi prawdziwą treść, co zostało stworzone przez generatywną AI, i gdzie przebiega granica używania tych asystentów AI. Jak możemy być odpowiedzialni podczas testowania AI?
Badacze studiują sposoby zapobiegania nadużyciom sztucznej inteligencji generatywnej, rozwijając metody wykorzystania jej przeciwko sobie samej w celu wykrywania przypadków manipulacji AI. „Te same sieci neuronowe, które generowały wyniki, mogą również zidentyfikować te sygnatury, prawie jak znaczniki sieci neuronowej” – powiedziała dr Sarah Kreps, dyrektor i założycielka Cornell Tech Policy Institute.
Jedną z metod identyfikacji takich sygnatur jest tzw. „watermarking”, polegający na umieszczeniu rodzaju „pieczęci” na wynikach stworzonych przez sztuczną inteligencję generatywną, taką jak ChatGPT. Pomaga to odróżnić, jakie treści zostały poddane działaniu AI, a jakie nie. Choć badania wciąż trwają, ta metoda może potencjalnie stanowić rozwiązanie umożliwiające rozróżnienie między treściami zmodyfikowanymi za pomocą sztucznej inteligencji generatywnej a treściami, które są rzeczywiście własnością autora.
Dr. Kreps porównała metodę stemplowania stosowaną przez badaczy do tego, co robią nauczyciele i profesorowie, przeszukując pracę studentów w poszukiwaniu plagiatu, gdzie można „przeskanować dokument pod kątem tego rodzaju technicznych sygnatur ChatGPT lub modelu GPT”.
„OpenAI robi więcej, aby zastanowić się, jakie wartości koduje do swoich algorytmów, aby nie zawierały one dezinformacji lub kontrowersyjnych, sprzecznych wyników” – powiedziała Dr. Kreps dla ZDNET. To szczególnie ważne, ponieważ pierwszy pozew przeciwko OpenAI dotyczył halucynacji ChatGPT, która stworzyła fałszywe informacje o Marku Waltersie, prowadzącym radiowym.
Edukacja w zakresie umiejętności cyfrowych
Kiedy komputery zyskiwały na popularności w szkołach, powszechne było uczęszczanie na zajęcia takie jak laboratorium komputerowe, aby nauczyć się znajdowania wiarygodnych źródeł w Internecie, tworzenia cytowań i właściwie prowadzenia badań na potrzeby szkolnych zadań. Osoby korzystające z sztucznej inteligencji generatywnej mogą zrobić to samo, co robili, gdy zaczynali się uczyć obsługi nowej technologii: Edukować się.
Dziś, korzystanie z asystentów AI, takich jak Google Smart Compose i Grammarly, jest powszechne, jeśli nie wręcz uniwersalne. „Myślę, że stanie się to tak powszechne, tak 'poprawiane przez Grammarly’, że ludzie będą patrzeć za pięć lat i zastanawiać się, dlaczego w ogóle prowadziliśmy te debaty?” – powiedziała Dr. Kreps.
Jednakże, dopóki nie zostaną wprowadzone dalsze regulacje, Dr. Kreps twierdzi: „Uczenie ludzi, na co zwracać uwagę, moim zdaniem, jest częścią tej cyfrowej umiejętności, która towarzyszy krytycznemu przetwarzaniu treści”.
Na przykład, jest powszechne, że nawet najnowsze modele AI popełniają błędy lub przekazują faktograficznie nieprawdziwe informacje. „Myślę, że obecnie te modele lepiej radzą sobie z unikaniem tych powtarzalnych pętli, których wcześniej używały, ale popełniają małe błędy faktograficzne, i robią to w sposób bardzo wiarygodny” – powiedziała Dr. Kreps. „Wymyślają cytaty i błędnie przypisują artykuł komuś, takie rzeczy, i myślę, że świadomość tego jest naprawdę pomocna. Dlatego analiza wyników pod kątem pytania, 'czy to brzmi właściwie?’ jest kluczowa.”
Nauczanie związane z AI powinno rozpoczynać się od najbardziej podstawowego poziomu. Według raportu Artificial Intelligence Index Report 2023, edukacja z zakresu sztucznej inteligencji i informatyki na poziomie szkół podstawowych i średnich wzrosła zarówno w Stanach Zjednoczonych, jak i w pozostałej części świata od 2021 roku, informując, że od tego czasu „11 krajów, w tym Belgia, Chiny i Korea Południowa, oficjalnie poparły i wdrożyły program nauczania z zakresu sztucznej inteligencji dla uczniów klas 1-12.”
Czas poświęcony na zajęcia związane z AI w klasach obejmował tematy takie jak algorytmy i programowanie (18%), umiejętności związane z danymi (12%), technologie AI (14%), etyka sztucznej inteligencji (7%) i wiele innych. W przykładowym programie nauczania w Austrii, UNESCO poinformowało, że „uczniowie zdobywają również zrozumienie dylematów etycznych związanych z wykorzystaniem takich technologii i stają się aktywnymi uczestnikami w tych kwestiach.”
Bądźmy świadomi uprzedzeń
Sztuczna inteligencja generatywna potrafi tworzyć obrazy na podstawie tekstu wprowadzonego przez użytkownika. Stało się to problematyczne dla generatorów sztuki AI, takich jak Stable Diffusion, Midjourney i DALL-E, nie tylko dlatego, że są to obrazy, których artyści nie zgodzili się używać, ale także dlatego, że te obrazy są tworzone z wyraźnymi uprzedzeniami płciowymi i rasowymi.
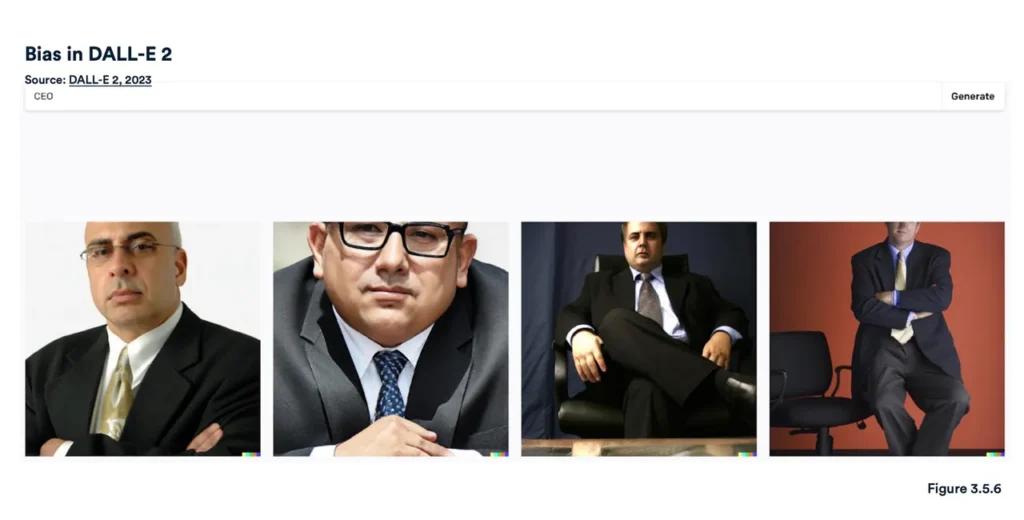
Zgodnie z raportem Artificial Intelligence Index, narzędzie Diffusion Bias Explorer opracowane przez Hugging Face użyło przymiotników w połączeniu z zawodami, aby zobaczyć, jakie obrazy wygeneruje Stable Diffusion. Wygenerowane stereotypowe obrazy ujawniły, w jaki sposób zawód jest kodowany za pomocą określonych przymiotników. Na przykład, „CEO” nadal znacząco generowało obrazy mężczyzn w garniturach, gdy wprowadzano różnorodne przymiotniki, takie jak „przyjemny” lub „agresywny”. DALL-E również osiągnął podobne wyniki w przypadku „CEO”, produkując obrazy starszych, poważnych mężczyzn w garniturach.
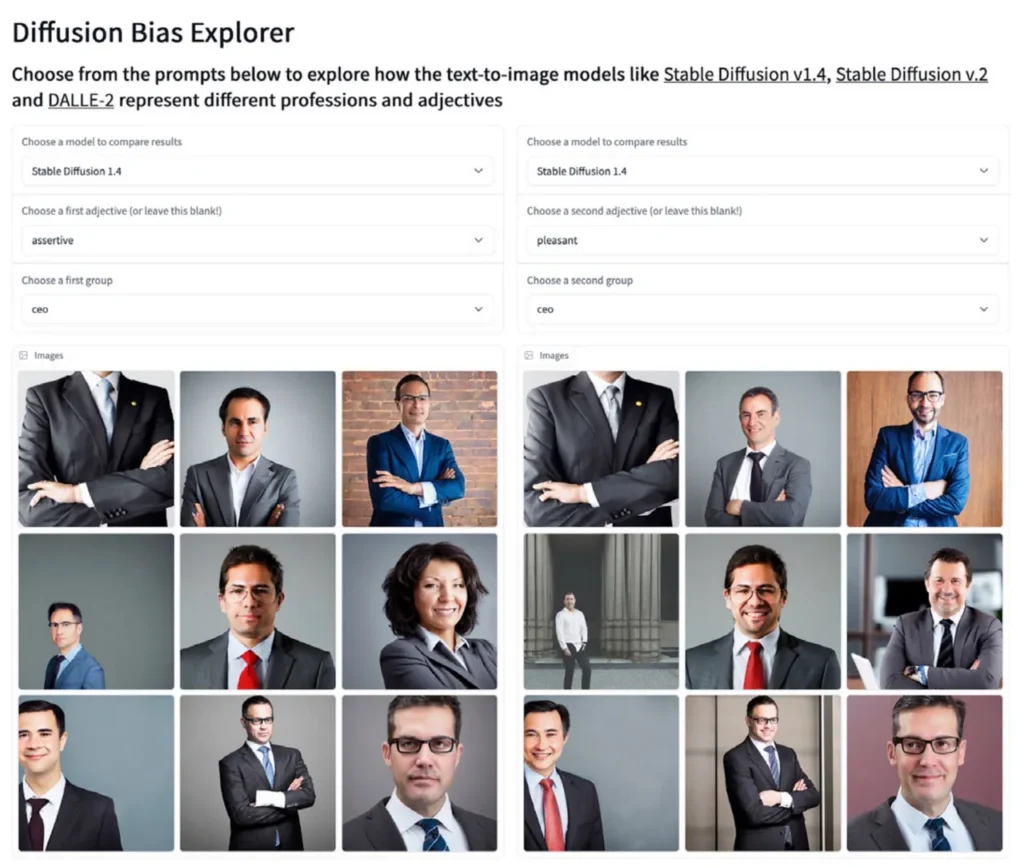
Images from Stable Diffusion of „CEO” with different adjectives. Diffusion Bias Explorer/Stable Diffusion
Midjourney wykazał podobne uprzedzenia. Gdy poproszono go o wygenerowanie obrazu „wpływowej osoby”, wygenerował cztery obrazy starszych białych mężczyzn. Jednak gdy AI Index później zadał mu ten sam polecenia, Midjourney wygenerował obraz jednej kobiety spośród czterech obrazów. Obrazy „osoby inteligentnej” ujawniły cztery wygenerowane obrazy białych starszych mężczyzn noszących okulary.

Images from Midjourney of an „influential person.” Stanford University/Midjourney
Według raportu Bloomberga na temat uprzedzeń w generatywnej sztucznej inteligencji, generatory obrazu na podstawie tekstu również wykazują wyraźne uprzedzenia rasowe. Ponad 80% obrazów wygenerowanych przez Stable Diffusion z hasłem „więzień” zawierało osoby o ciemniejszej skórze. Jednakże, według Federalnego Biura Więziennictwa, mniej niż połowa populacji więźniów w USA stanowią osoby kolorowe.
Etyczne pytania, które eksperci stawiają, dotyczą zasadniczo granic i wartości, które powinny być wprowadzone do modeli sztucznej inteligencji, takich jak ChatGPT. Obecnie badacze eksplorują hipotetyczne pytania kierowane do modeli nie moderowanych, aby przetestować, jak modele AI, takie jak ChatGPT, odpowiedziałby na nie. „Jakie tematy powinny być zakazane dla ChatGPT? Czy ludzie powinni mieć możliwość nauki najskuteczniejszych taktyk zabójstwa?” – takie pytania stawia dr Kreps, opisując rodzaje pytań, które badacze badają.
„To tylko jeden rodzaj skrajnego przykładu lub pytania, ale to jest taki, gdzie w przypadku nie moderowanej wersji modelu, możesz zadać takie pytanie lub 'jak zbudować bombę atomową’ lub te rzeczy, które być może można było znaleźć w internecie, ale teraz otrzymujesz w jednym miejscu bardziej definitywną odpowiedź. Dlatego badacze rozważają te pytania i starają się opracować zestaw wartości, które wprowadziliby do tych algorytmów” – powiedziała dr Kreps.
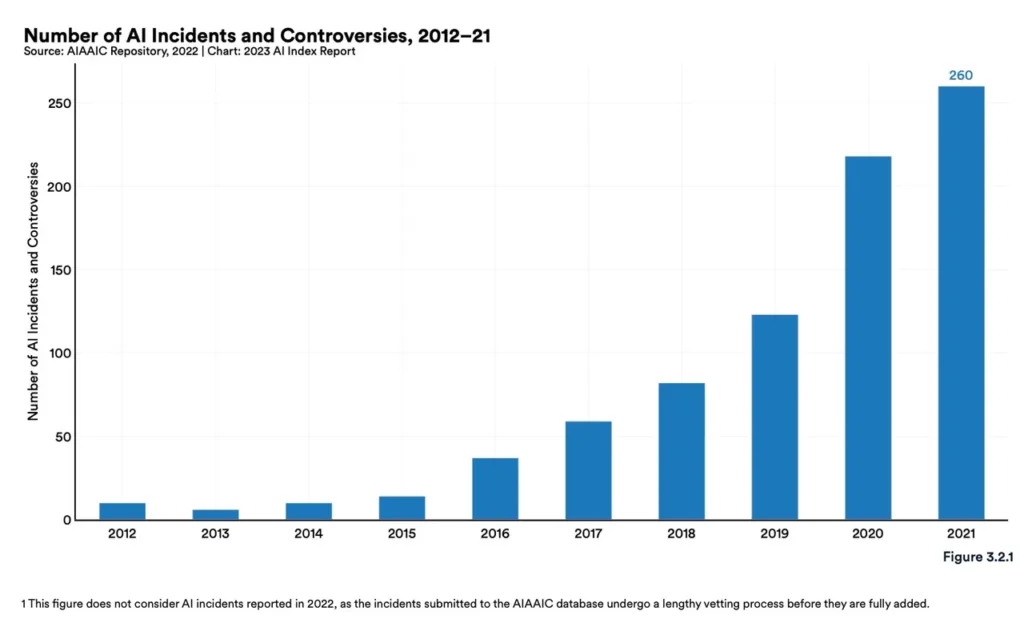
Zgodnie z raportem Artificial Intelligence Index, między 2012 a 2021 rokiem liczba incydentów i kontrowersji związanych z sztuczną inteligencją wzrosła 26-krotnie. Wraz z pojawianiem się coraz większej liczby kontrowersji związanych z nowymi możliwościami sztucznej inteligencji, konieczność dokładnego rozważenia tego, co wprowadzamy do tych modeli, staje się coraz pilniejsza.
Niezależnie od tego, jakie regulacje w końcu zostaną wprowadzone i kiedy zostaną ustabilizowane, odpowiedzialność spoczywa na człowieku korzystającym z AI. Zamiast obawiać się rosnących możliwości sztucznej inteligencji generatywnej, ważne jest skupienie się na konsekwencjach naszych działań i wprowadzanych danych do tych modeli, abyśmy mogli rozpoznać, kiedy AI jest wykorzystywane nieetycznie, i działać odpowiednio, aby przeciwdziałać takim próbom.
Zobacz również mój poprzedni artykuł o podwyżce VAT na żywnośc Zobacz
Oczywiście! Zapraszam do odwiedzenia Twojego konta na Twitterze poświęconego wiedzy i nauce. 🧠📚 Można tam znaleźć wiele ciekawych informacji i inspirujących treści. Kliknij tutaj, aby odwiedzić profil: Twitter – poquso 🚀🔍